
Чат-бот с искусственным интеллектом ChatGPT отвечает как обычный человек на любой вопрос, который вы задаёте в Google. На выходе получается ёмкий и полный текст, а писать можно как своему другу. Бояться, что вас не поймут, больше нет смысла.
Языковая модель талантливо схватывает контекст, его не надо разжёвывать. Боту скормили Википедию версии до 2021 года, миллионы статей, блогов и постов. ИИ владеет открытыми знаниями всего человечества на 11 языках, включая русский.
Бот от OpenAI:
пишет школьные сочинения о произведениях
пишет скрипты для анимаций
знает ответ на любой вопрос из Википедии
объясняет его по-человечески
схватывает контекст, который иногда не понимает даже человек
заменяет поисковик
описывает фантастические декорации
придумывает игры в новом жанре, выдаёт сценарий к фильму
раскладывает мотивацию героев в книгах
переводит текст как профессионал
выдаёт краткое содержание работ
заботливо поясняет сложные термины
поддерживает разговор
вспоминает прошлые ответы
верстает ответы
редактирует ответы по правкам
нумерует списки
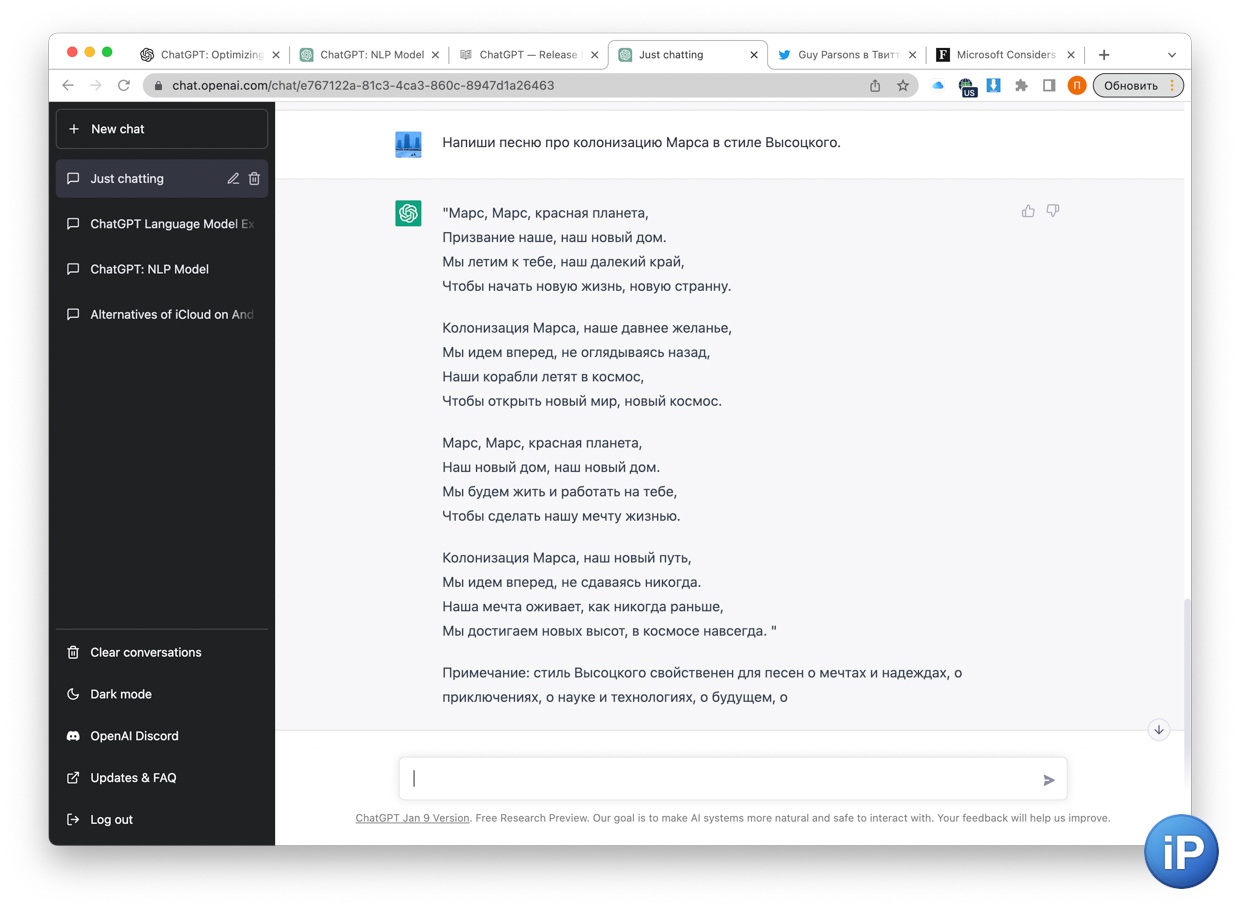
пишет песни в любом стиле
пишет код
делает речь для рекламы
и презентации продуктов
и много другого.Делает это на английском (основной, отвечает быстрее), русском, китайском, испанском, французском, немецком, итальянском, португальском, немецком, датском, японском и корейском языках.
ChatGPT разработала некоммерческая организация OpenAI. Её основал Илон Маск с партнёрами, Microsoft только что вложила в компанию $10 млрд, а Google очень боится её нового ИИ, потому что на фоне него поисковик напоминает технологии прошлого века.
Ниже простым языком, по этапам и на примерах рассказываю, как получается магия.
Если объяснять ребёнку на игрушках
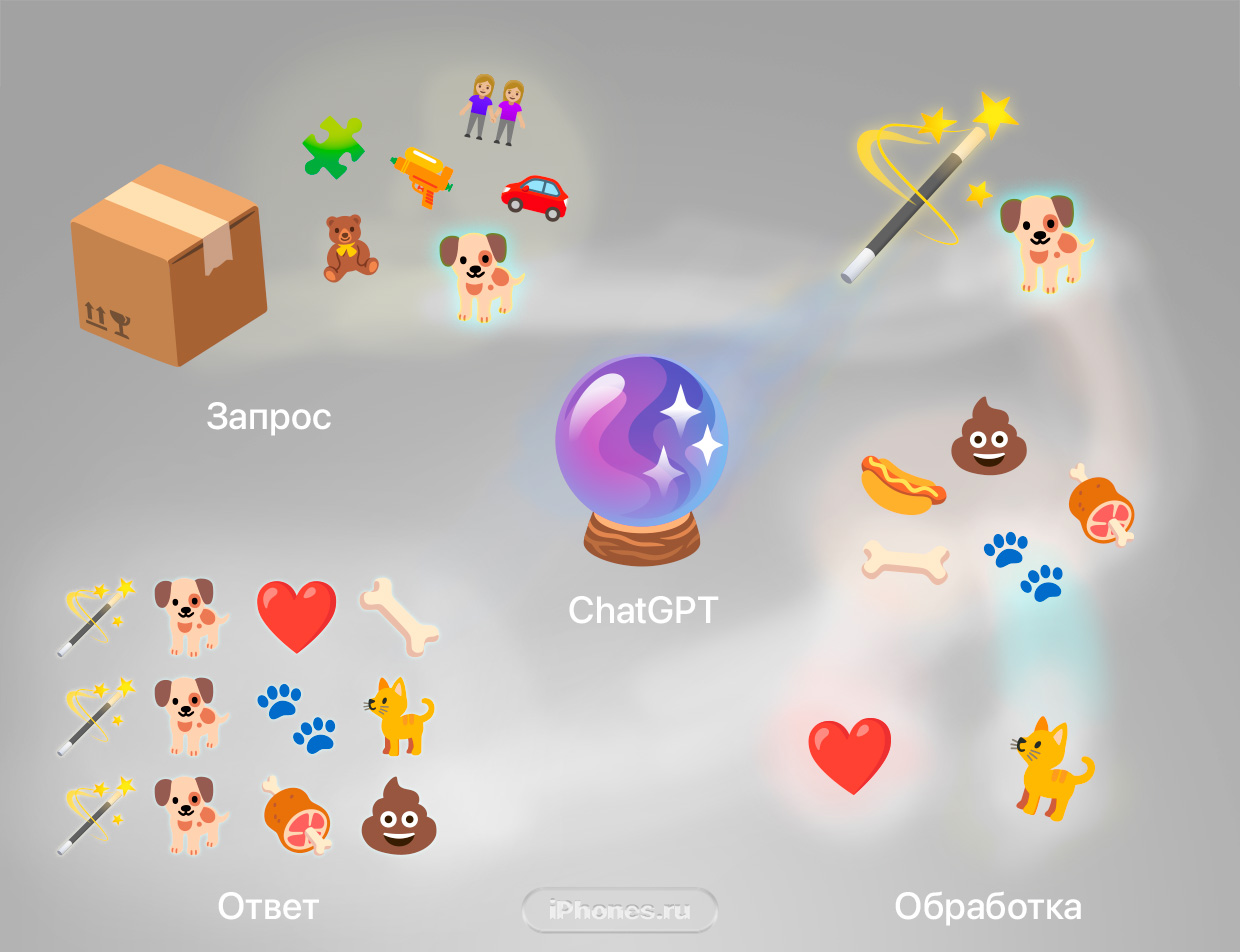
ChatGPT – это компьютерная программа, которая может разговаривать с вами и понимать, что вы говорите. Работает как магический шар: озвучиваете, что хотите, а она отвечает предложением со смыслом.
Представьте, что у вас есть ящик с игрушками, внутри которого много разных кукол, машинок и фигурок.
Каждая игрушка это слово. Когда вы достанете оттуда игрушку, компьютер посмотрит на неё и попытается выяснить, какие еще игрушки подойдут к ней. Точно так же он по слову составляет осмысленное предложение.
Например, если вы возьмёте игрушку «собака» и отдадите её компьютеру, он будет смотреть и думать о том, какие слова часто стоят после «собака». И найдёт такие, как «лаять», «бегать» или «гоняться». А потом выберет лучшее.
В итоге программа может сказать «Собака залаяла», «Собака бежит» или «Собака гонится за мячиком».
ChatGPT способен на это, потому что его «обучили» люди, которые дали ему очень много предложений из жизни людей. Благодаря этому он знает, какие слова обычно сочетаются друг с другом в предложениях. И умеет, как настоящий учёный, их собирать в умные ответы.
Теперь рассмотрим сжатый и более взрослый вариант ответа.
Коротко. ChatGPT учила не текст, а смысл
Поэтому каждое новое сообщение это не отрывок выученной базы, а оригинальный текст. С советом фильма но вечер, например
Ключевую роль в этой языковой модели играет архитектура трансформера.
С помощью неё программа сначала много раз обрабатывает введённый вами текст, а затем на основе полученного результата также через разные слои генерирует ответ. На каждом шаге она постоянно сверяется со своими навыками, чтобы оценить, правильно ли всё делает.
Во время обучения модель не запоминает добавленные в неё куски текста и не подбирает из памяти нужный. Нет, она учится понимать вес каждого слова в предложении и распознавать важность их порядка, то есть где какое должно стоять.
Например, во фразе «Советский Союз продержался до 1991 года» и в её переводе «The Soviet Union held out until 1991» нейросеть составляет тепловую карту слов, близких по смыслу.
«Советский» и «Союз» стоят рядом, поэтому на английском они близки к словосочетанию Soviet Union, а не к дословному Union of Advisers (Advise – тоже «совет»).
Также слова «советский», «союз» и «продержался» стоят рядом, поэтому «продержался» перевелось как абстрактное и масштабное «held out», применимое к государству.
Пример с похожими словами, но с другим смыслом полностью меняет контекст.
Вот фраза «Их союз продержался всего два года, и никакие советы не помогли» и её перевод «Their union lasted only two years, and no advice helped».
Слово «союз» и «советы» связаны уже никак не будут, потому что находятся далеко друг от друга, а синтаксически соотносятся плохо. Поэтому «советы» переведётся как advice (в единственном числе, потому что ChatGPT знает, что говорит на английском).
Также рядом с «продержался» стоит «союз», подразумевающий по смыслу «брак» или «сотрудничество», поэтому переводится как более камерное и житейское «lasted».
Такую разницу легко объяснить даже ребёнку, а вот компьютеру для этого нужны особые инструменты, которые можно будет масштабировать на любой ведённый текст.
Вот как именно это придумали в OpenAI.
Что происходит с текстом шаг за шагом
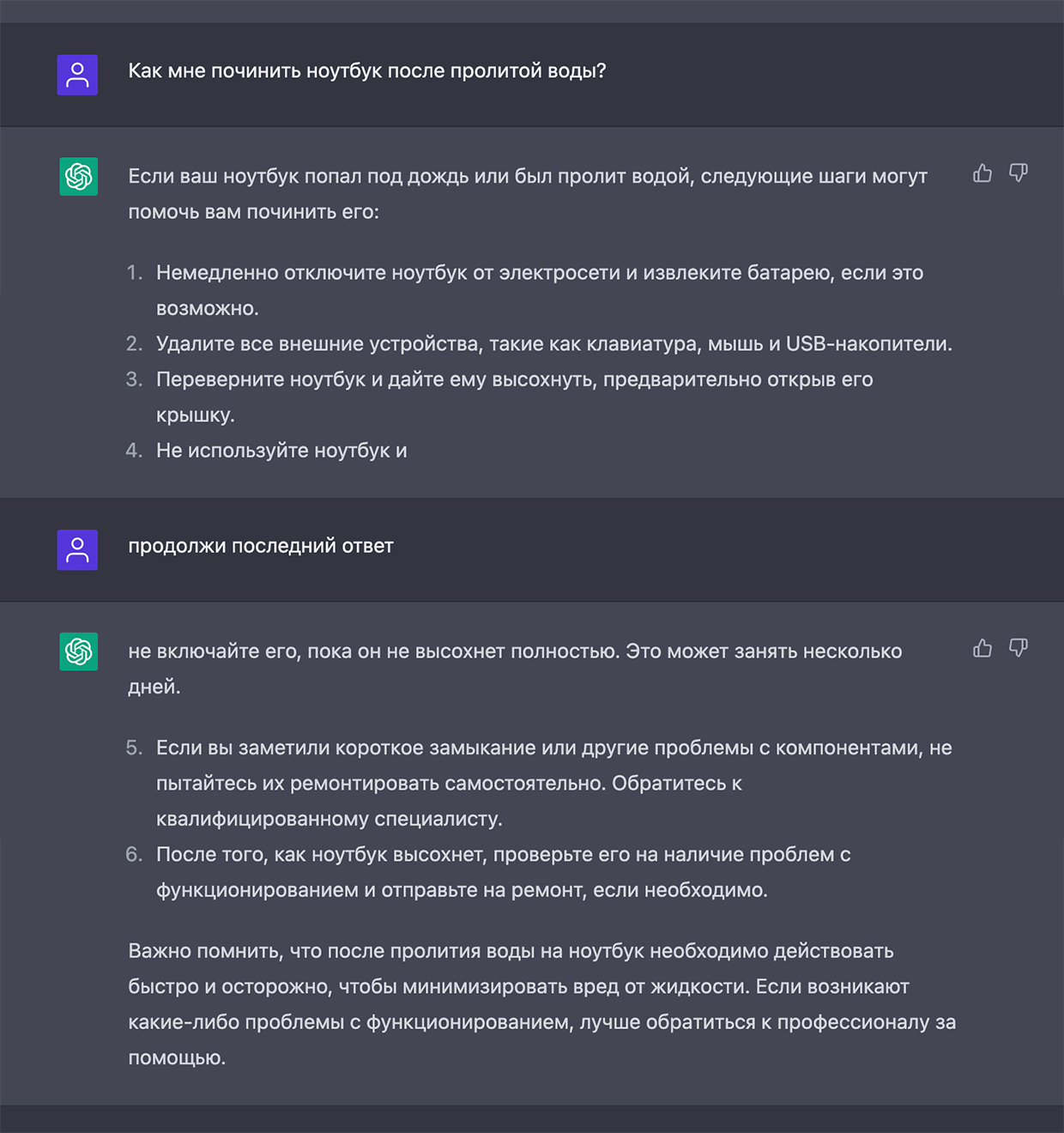
Разбираем вот такой вопрос. На русском языке ChatGPT часто прерывает ответ, но его всегда можно попросить продолжить
GPT в названии ChatGPT переводится как Generative Pre-trained Transformer. На русском значит «натренированная модель, которая генерирует текст». Модель из разбора работает на версии GPT 3.5, хотя сам чат это отрицает.
Процесс можно описать разными этапами. Дело в том, что ChatGPT, как и DALL·E 2, это не один простой и прямолинейный ИИ, а большая программа из десятка компонентов, разработанных и отточенных сначала в Google, а потом в OpenAI.
Не было такого, что создатели собрали несколько готовых механизмов, прогнали через них огромную базу знаний и получили одного работающего бота. Его именно построили, объединяя в систему много компонентов.
Опишу процессы на среднем уровне сложности, поскольку дальше пришлось бы говорить категориями, которыми оперируют только создатели подобных моделей. Людям, не связанным с программированием, они будут уже непонятны.
Для простоты взял пять основных шагов его работы:
1. Слова в токены
2. Токены в векторы
3. Кодирование векторов
4. Взвешивание слов
5. Декодирование и генерация слово за словом.
Вот как выглядит каждый этап.

1. Токенизация. Введённый вами текст разбивается на слова и «подслова», то есть отдельные смысловые элементы. Они называются токены. Например, фраза «Как мне починить ноутбук после пролитой воды?» делится на «как», «мне», «по», «чинить», «ноутбук» «после», «про», «лит», «ой», «воды» и «?». Всего 11 токенов из 6 слов.
Это не совсем деление по частям речи. Скорее по смыслу.
Каждая такая часть слова в разной степени влияет на контекст. После обучения система сама определяет, насколько сильно.
«Починить» состоит из приставки «по» и глагола в начальной форме «чинить», а вот «пролитой» несёт приставку «про», корень «лит» и окончание «ой», говорящее о женском роде зависимого слова «вода».
Дополнительный алгоритм вырезает некоторые токены, чтобы уменьшить запрос без потери смысла. Например, фраза «Как чинить ноутбук после воды?» несёт тот же контекст, зато вырезаны целых пять токенов: «мне», «по»[чинить],«про», «лит» и «ой».
Упрощение может пойти ещё дальше, убрав окончание у «воды», слово «как» и пунктуацию «?».
В итоге предложение «Чинить ноутбук после вода» хоть и не совсем похоже на человеческое, но его смысл понятен. Теперь модель присуждает каждому слову его обозначение как части речи и записывает их отдельным слоем:
«Чинить [глагол] ноутбук [существительное] после [предлог] вода [существительное]».
Далее токены «шифруются», то есть переводятся на язык компьютеров.

2. Векторизация. Получившиеся токены превращаются в векторы. Выглядят как набор цифр. Это делает специальная нейросеть на основе «измерений», созданных ею самой во время обучения.
Условно, токен «чинить» будет выглядеть как 0.009 0.074 0.006 -0.094 0.001. Но слово шифруется не по буквам, а по образному значению.
Представьте отрезок, в начале которого токен со смыслом «человек» (0), далее токен со смыслом «чинить», а в конце токен со смыслом «совершённость»(1). Нейросеть решила, что на этом отрезке «чинить» настолько же близко к «человеку» как 0.009 близко к слову 1. И что оно настолько же близко к слову «совершённость», то есть что-то «сделанное до конца » как 0.074 близко к 1. То есть чуть ближе, но всё равно далеко. Отрицательное число значит, что «чинить» так далеко от, допустим, «разбирать», что в какой-то степени является антонимом этого слова.
Причём понятия «человек», «совершённость» и «разбирать» я ввёл для вашего удобства, на самом деле нейросеть, которая превращает токены в векторы, может иметь совершенно другие точки, на которые опирается.
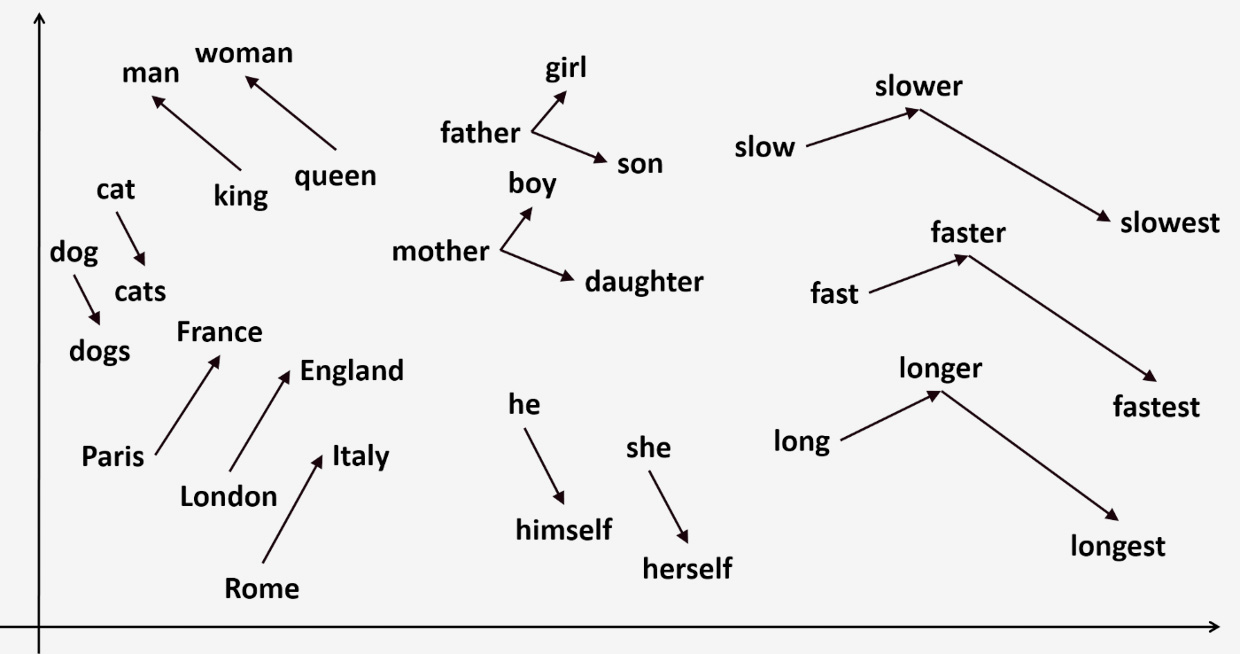
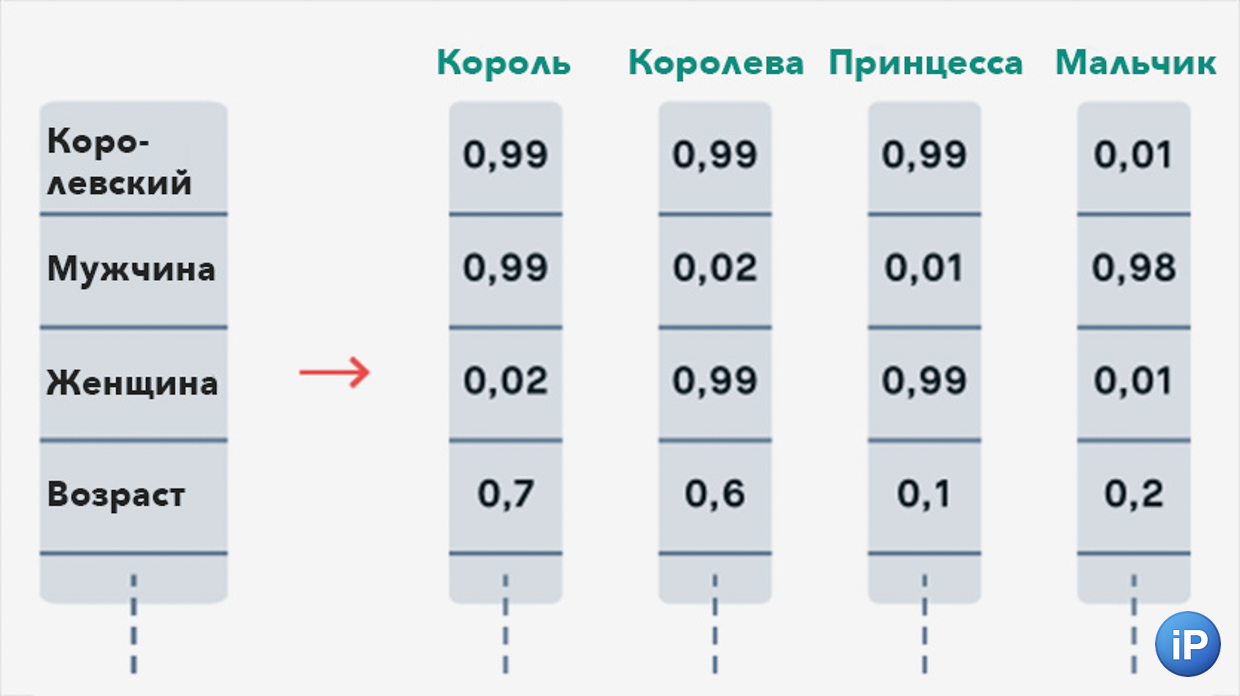
Векторные значения соотносятся приблизительно таким образом
На языке векторов говорят остальные элементы бота ChatGPT, поэтому перевод необходим для генерации текста.
Оптимизацию проводят даже тут. Чтобы улучшить качество обработки и в два раза сократить расходы, 15 декабря 2022 года OpenAI начала использовать модель text‑embedding‑ada‑002, объединяющую в себе пять ранее отдельных процессов (например, поиск введённого текста, нахождение сходства внутри текста и поиск кода для перевода).
На следующем этапе векторы влетают в «цех», который разными способами лепит из них чертёж будущего ответа.
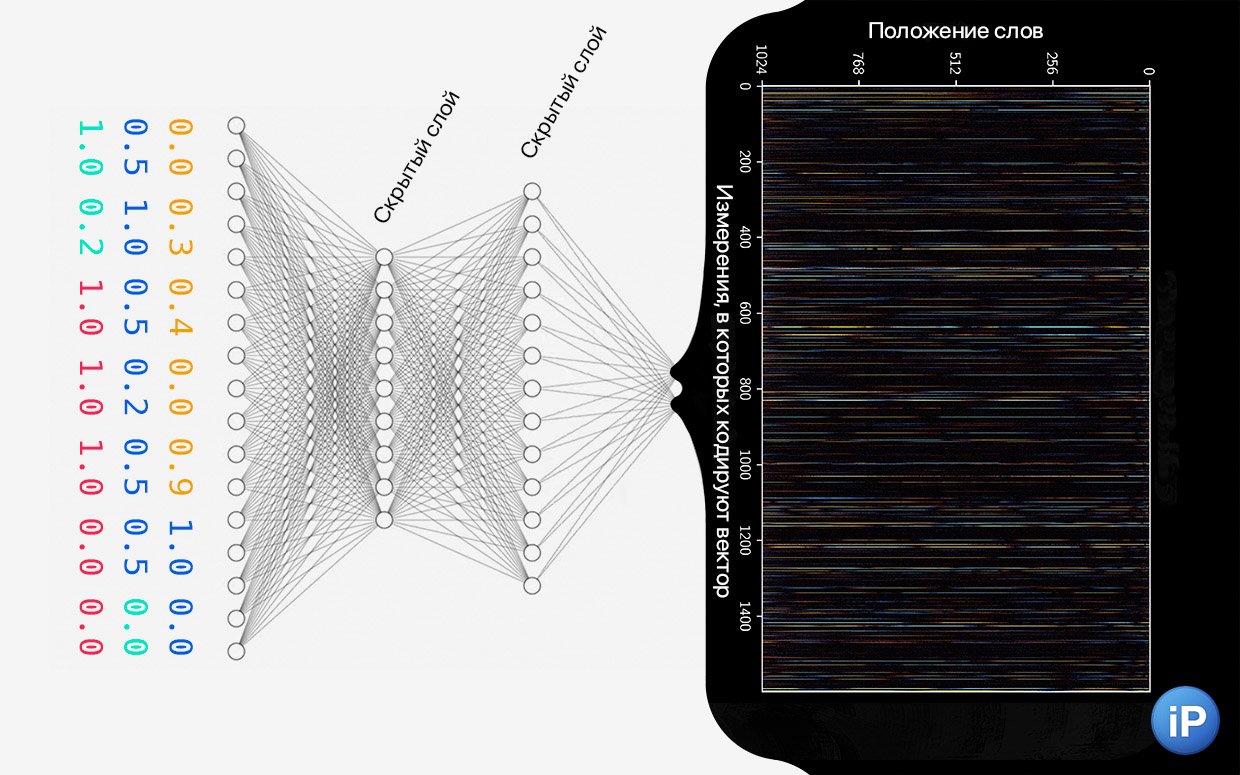
Векторы проходят через несколько скрытых слоёв. Скрытые, потому что только нейросеть знает, как они работают – она сама создала их. На чёрном фоне визуализация этого процесса
3. Кодирование данных. В работу вступает ключевая технология, благодаря которой ChatGPT пишет реалистичный текст.
Почему переводы Google, Яндекса и других в 2010‑х выглядели смешно? Потому что для обработки текста, допустим, с русского на английский использовались реккурентные нейронные сети (RNN), которые последовательно переводили каждое слово и составляли из них предложения.
Они не учитывали весь контекст разом, а позже делали это слабыми, неэффективными способами.
Заметили, что в последние годы переводчик Google похорошел? У него новый «движок».
Такой метод обработки текста меняет всё. Он называется «трансформеры». Разработан в том же Google как раз для того, чтобы улучшить перевод.
Трансформеры прогоняют набор цифр (векторы) из прошлого шага через несколько слоёв кодирования.
Упрощённо говоря, один слой разбирается, как каждое введённое слово соотносится с другим, чтобы понять ход мысли. Другой слой генерирует тему обсуждения, на которой будет базироваться ответ. Третий слой объединяет эти данные и соотносит их с разными параметрами или измерениями (категориями мышления). Но этих слоёв намного больше.
Получаются группы цифр в компактной и ёмкой форме, которые хорошо поймут ИИ-модели на следующем этапе.

4. Взвешивание слов. Задача на этом этапе оценить контекст и предсказать лучшую последовательность слов для ответа.
В предложении «Чинить ноутбук после вода» важность каждого слова для контекста будет приблизительно такая:
чинить > 0,7 ноутбук > 0,9 после > 0,1 вода > 0,5.
Но помните, что все слова выше уже зашифрованы и для программы выглядят совсем иначе.
Центральное слово «ноутбук» (0,9) ключевое. Во всей изученной смысловой библиотеке ChatGPT оно возбуждает блок слов, которые с ним связаны.
Зависимое от «ноутбука» «чинить» (0,7) превращает вписанный текст в просьбу, на которую ожидается ответ. Оно менее важное, но всё ещё играет формирующее значение и задаёт манеру ответа.
Слово «вода» (0,5) сужает список советов, поскольку добавляет описанной проблеме специфику.
А предлог «после» (0,1) нужен, чтобы связать другие существительные и очертить обстоятельства, при которых возник смысл. Он нужен, но меньше, чем все остальные.
Учитывая эти данные, модель формирует нужные по контексту новые векторы, которые в процентом соотношении как можно лучше соотносятся с векторами из вашего первичного запроса.
Далее трансформенный декодер (transformer decoder) приступает к созданию текста.
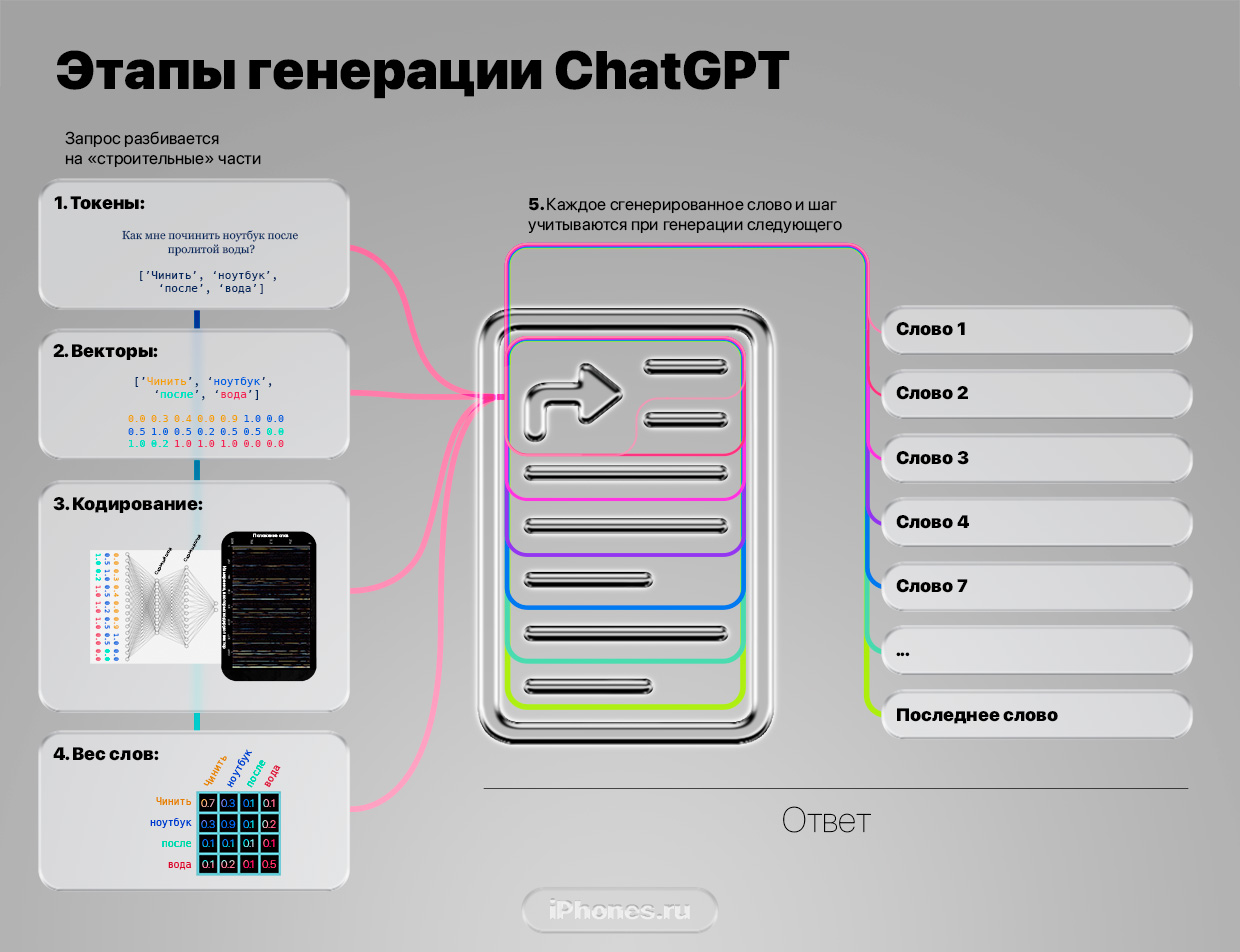
5. Декодирование и генерация текста. Когда формируется ответ, ChatGPT берёт во внимание всё: введённые изначально слова, их упрощенную версию в виде токенов и векторов, смысловую базу знаний с подходящими словами после тренировки, закодированные токены, декодированные, ответ, который модель собирается написать и даже ответ, который начала писать.
Когда текст наконец проявляется, эти факторы все вместе взвешиваются по отношению друг к другу, отсюда точность, ёмкость и корректность.
Ответ формируется не одновременно, волшебным образом складываясь из раскодированных цифр.
Итоговый результат генерируется по одному слову за раз. После каждого слова уже написанная часть отправляется обратно для оценки, добавляя ещё один фактор в генератор. Уже написанный текст снова взвешивается, и учитывает вместе с факторами выше при создании следующего. И так до тех пор, пока бот не сгенерирует токен «стоп».
Почему СhatGPT вообще умеет понимать контекст
Взвешивание будущего ответа начинается с конца введённого вами запроса
За время тестирования я заметил, что ChatGPT любит отвечать ёмко. Он начинает ответ, по-новому формулируя вопрос, разжевывает мысль, берёт во внимание основные и иногда неочевидные обстоятельства.
Несколько факторов создают чудо.
Языковую модель тренировали на 45 ТБ текста, это 225 млрд слов из книг, сайтов, блогов и Википедии. ChatGPT изучал закономерности, при которых слова находились рядом друг с другом. Это помогает модели понимать контекст введённого текста и генерировать ответ, связанный с темой.
Работают два механизма внимания сразу: один (self-attention) оценивает ответ нейросети прямо во время написания, а второй (cross-attention) сравнивает запрос человека и ответ, который пишет модель. Каждое слово на выдаче «взвешивается» по отношению к введённому запросу, к самому себе и к слоям сгенерированного кода между ними.
Например, при обучении в предложении «Я люблю играть в футбол в парке» и ответе на него «Я люблю играть в футбол в парке, это моё любимое занятие» ChatGPT даёт такую оценку каждому слову:
я > 0,1 люблю > 0,3 играть > 0,5 в > 0,2 футбол > 0,8 в > 0,2 парке > 0,9 это > 0,1 моё > 0,2 любимое > 0,8 занятие > 0,7. Числа показывают значимость каждого слова в разговоре. Модель определила, что «футбол», «парк», «любимое» и »занятие» несут в себе больше всего смысла.
Такой разбор не значит, что слова делятся на «важные» и «не важные». Нет, выстраивается градация, по которой алгоритм формирует закономерности связей в предложении.
Это нужно для того, чтобы правильно работало декодирование. Поскольку нейросеть постоянно оценивает то, что говорит, она должна генерировать не весь ответ сразу, а слово за словом.
То есть ChatGPT, прямо как люди, выстраивает речь постепенно, а не одним абзацем в секунду. И благодаря пониманию, что в теме более важно, а что менее, способна держать генерируемый текст в пределах заданного контекста.
Помимо архитектуры важно и то, что при обучении некоторые модули ChatGPT корректировались человеком, а затем использовались с той же целью для остальных частей бота. Выглядело это приблизительно так:
📝 В первую очередь, на тренировочные запросы реальные люди писали идеальный ответ, метод называется The Supervised Fine-Tuning. Модель училась сопоставлять пары по смыслу. Качественный, но дорогой способ. Его результаты использовались для второго этапа.
⚖️ Далее создатели бота разработали «модель поощрения» (The Reward Model, RM). На текстовый запрос будущий ИИ генерировал несколько ответов, которые затем реальные люди оценивали от лучших к худшим. Способ не требует создания новый данных людьми, поэтому его проще масштабировать при обучении.
♻️ Третьим этапом тренировки была «оптимизация политики» Proximal Policy Optimization. Автоматизированный процесс, когда на запрос ИИ генерирует ответ, но вместо того, чтобы остановиться на нём, сама оценивает его вместо человека.
Взаимосвязь методов формирует органичную речь, близкую к человеческой. Огромный массив данных позволяет ей на основе этой сложной сети из своих знаний вытягивать то, что действительно нужно сказать. Таким образом, чтобы соблюдался такт разговорного языка, грамотность и даже вёрстка, включая деление по абзацам, нумерация и выделение блоками в контексте.
ИИ захватывает мир?
Такие вступления из 9 класса в статью не пойдут. Хотя правки ChatGPT вносит весело и резво
Не всё так просто. Обслуживание запросов и генерация контента дорого стоит. Несмотря на намерение OpenAI использовать разработки в благих целях и в желании оградить новые технологии от больших корпораций, оперировать ящиком Пандоры без серьёзных бюджетов невозможно.
После недели слухов Microsoft инвестировала $10 млрд в OpenAI. Это вложение оценивает разработчика DALL·E 2 и ChatGPT в $29 млрд.
ChatGPT сделал шум, потому что сейчас он в открытом тестировании, и больше миллиона человек получили доступ к нему бесплатно.
Фактически бот дорогой. Выше я описывал, что нейросеть превращает слова и их части в токены. В среднем на 750 слов получается 1000 токенов. В этой статье приблизительно 3500 токенов. То есть выдача подобного ответа на вопрос «Как работает ChatGPT и что он умеет?» в пяти ответах (вы же уточните подробности) обошлась бы от $0,0014 до $0,42 в зависимости от языковой модели, которую предлагает OpenAI.
Представим, что подобные запросы делает 1000 человек в минуту. Расходы получатся от $2016 до $604 800 в день или от $60 840 до $18 144 000 в месяц. И это только оплата за сам чат-бот без учёта других расходов на содержание сервиса.
Напомню, что Википедию для поиска информации посещает 8000 человек в секунду. До захвата мира далеко.
Установка речевых моделей в приложения, программы, операционные системы, игры, колонки, больницы, энциклопедии и куда угодно ещё будет сжигать деньги. А ведь в итоге мы, конечные потребители, должны за это платить.
Чтобы подобные чат-боты были везде как сейчас интернет, нужно оптимизировать затраты на их обслуживание.
Но возможности языковой модели мы увидели. Как и большие корпорации: Google бьёт тревогу и экстренно торопится показать свой аналог уже в 2023 году, поскольку теперь поисковик выглядит глупым. Microsoft вливает гигантские деньги в OpenAI и внедряет их наработки в свой поисковый движок и GitHub.
На пузырь, как с криптовалютой, это не похоже, а вот на мощный скачок в перестройке рабочей силы очень даже. Поэтому вопрос скорее стоит не «если», а «когда».
Текущий ответ: уже, но с оговорками. Как минимум до тех пор, пока ChatGPT доступен в свободном бета-тесте.
⤠ Как добавить нейросеть ChatGPT прямо в Сири (Siri) на iPhone. Переводит, решает задачи и даже пишет код
⤠ Как создать нейронный плейлист по любому запросу в Apple Music или Spotify. Теперь можно!





32 комментариев