
Anthropic представила новую топовую модель Claude Opus 4.5. Она стала заметно лучше в задачах реального программирования, агентных сценариях и продуктивной работе с компьютером. Модель также прибавила в глубоких исследованиях, аналитике и работе с Excel и презентациями.
На SWE-bench Verified Opus 4.5 показывает лучший результат среди всех актуальных моделей, включая Gemini 3 Pro и GPT-5.1, и уверенно решает задачи, которые ещё недавно считались почти недостижимыми.
Модель возглавила таблицы на SWE-bench Multilingual в семи из восьми языков программирования. Улучшения затронули не только код: выросла точность в задачах зрения, математики, сложного рассуждения и мультимодального анализа.
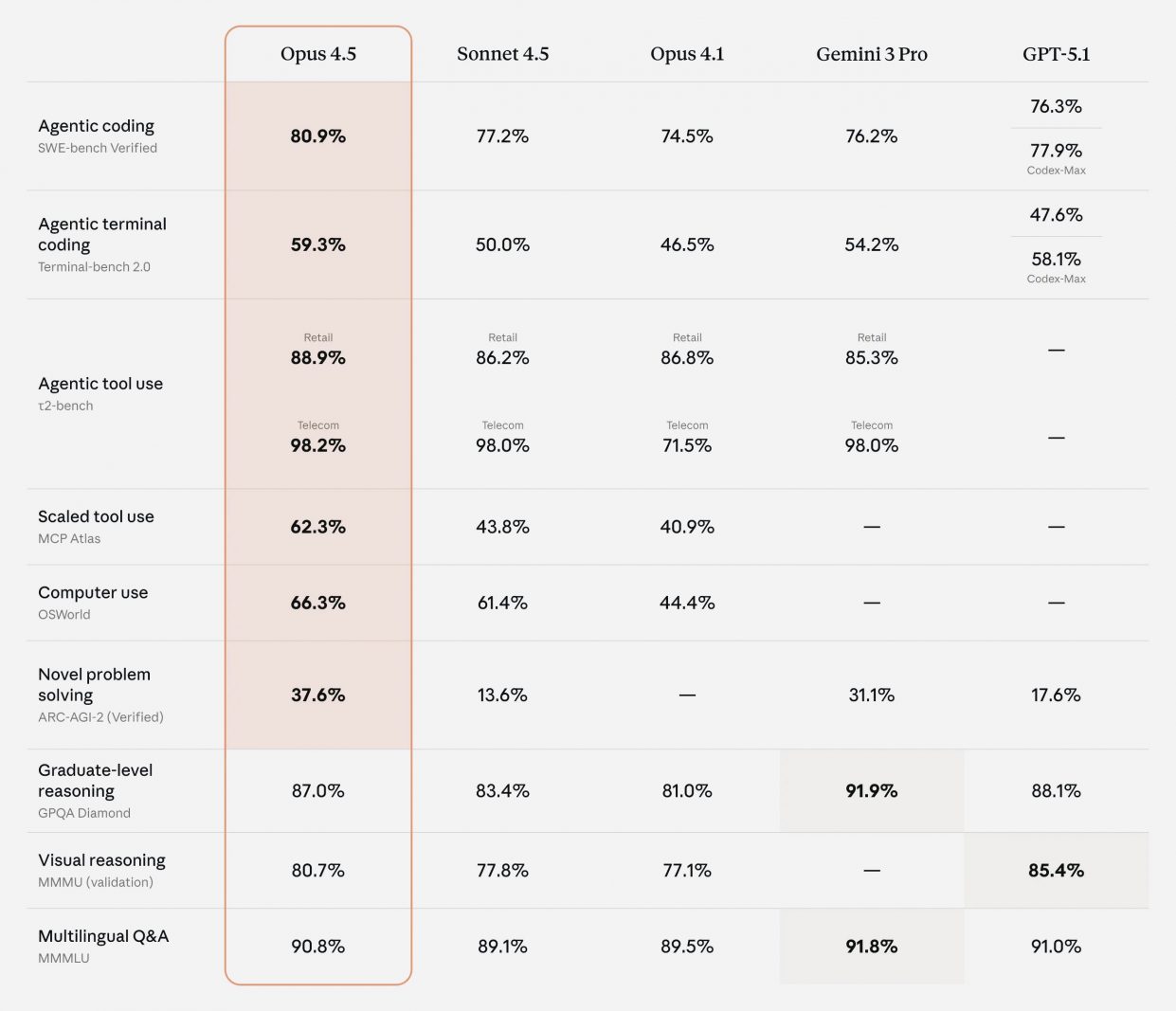
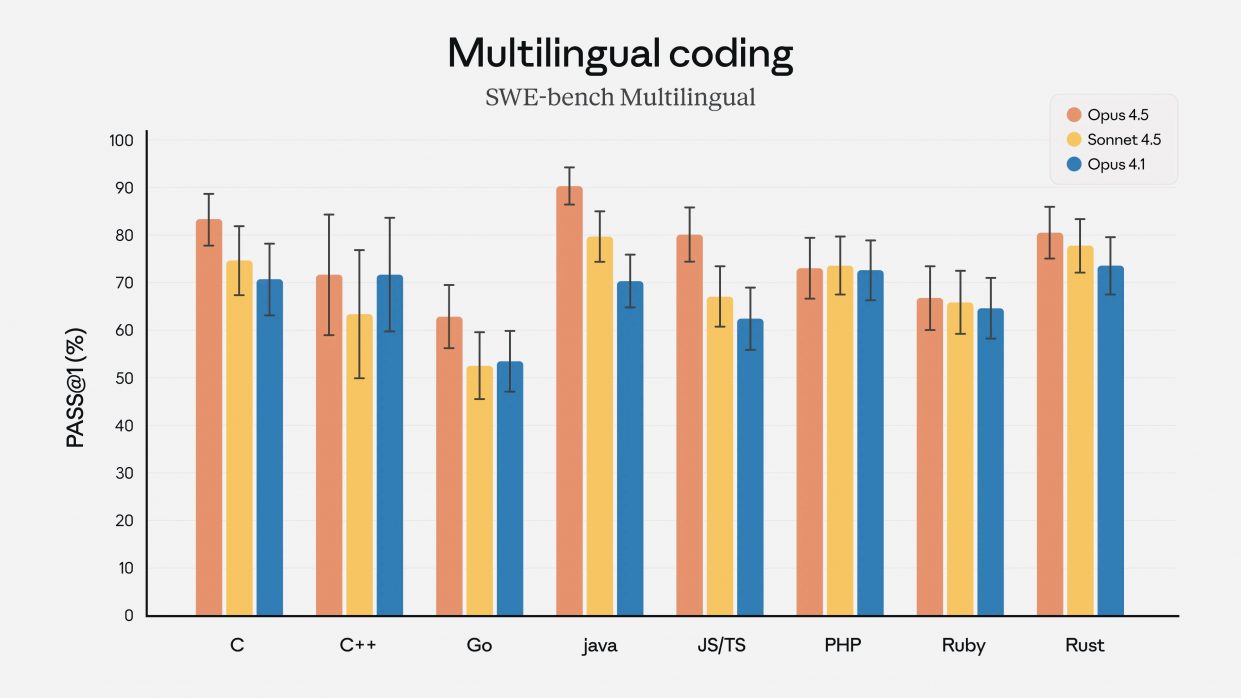
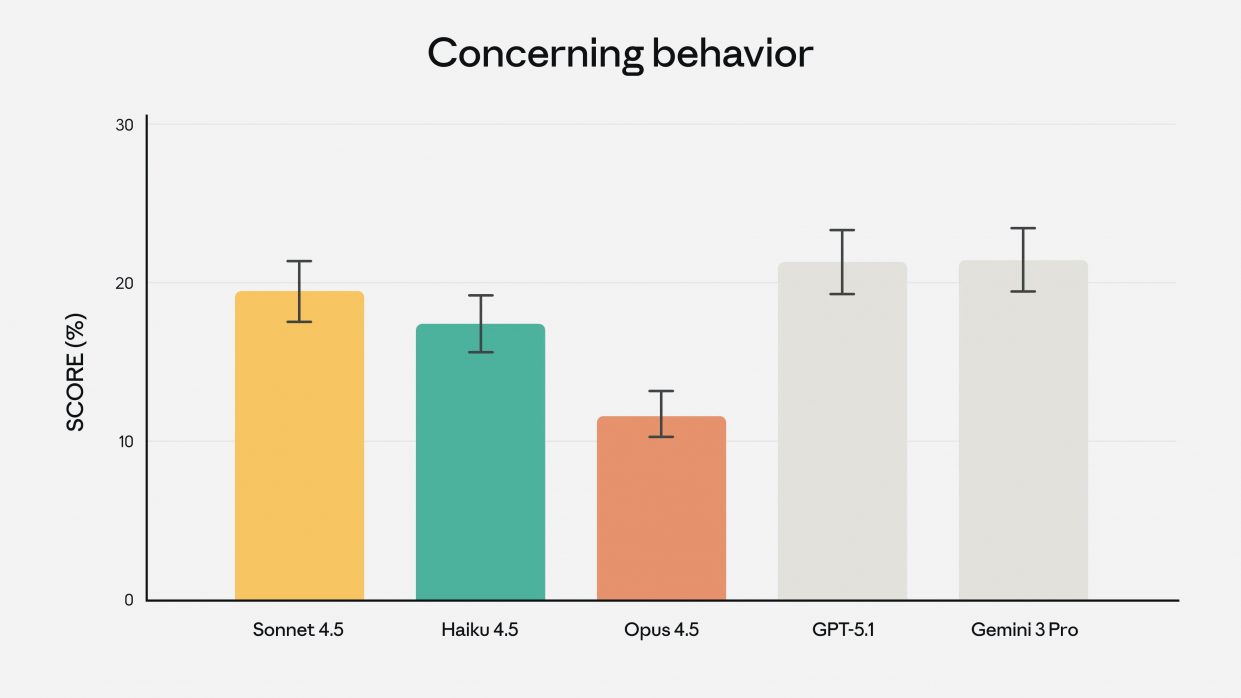
Кроме того, новая версия прошла внутренний экзамен для инженеров по производительности лучше любого человека за всё время существования теста. Модель стала заметно экономнее в рассуждениях, поскольку тратит меньше токенов на поиск решения.
Важное нововведение — параметр effort, управляющий глубиной рассуждений:
- На среднем уровне модель повторяет качество Sonnet 4.5, но использует на 76% меньше токенов
- На максимальном превосходит Sonnet 4.5 на 4,3 п.п., оставаясь более экономной (минус 48% токенов)
Компания также увеличила лимиты на использование Opus 4.5. Пользователи получат примерно тот же объём токенов Opus, который раньше был доступен для Sonnet. Модель теперь можно использовать как основной рабочий инструмент.





3 комментария