
БЕЗ скриптов, макросов, регулярных выражений и командной строки.
Эта статья пригодится студентам, которые хотят скачать все картинки с сайта разом, чтобы потом одним движением вставить их в Power Point и сразу получить готовую презентацию. Владельцам электронных библиотек, которые собирают новые книги по ресурсам конкурентов. Просто людям, которые хотят сохранить интересный сайт/страницу в соцсети, опасаясь, что те могут скоро исчезнуть, а также менеджерам, собирающим базы контактов для рассылок.
Есть три основные цели извлечения/сохранения данных с сайта на свой компьютер:
- Чтобы не пропали;
- Чтобы использовать чужие картинки, видео, музыку, книги в своих проектах (от школьной презентации до полноценного веб-сайта);
- Чтобы искать на сайте информацию средствами Spotlight, когда Google не справляется (к примеру поиск изображений по exif-данным или музыки по исполнителю).
Ситуации, когда неожиданно понадобится автоматизированно сохранить какую-ту информацию с сайта, могут случиться с каждым и надо быть к ним готовым. Если вы умеете писать скрипты для работы с утилитами wget/curl, то можете смело закрывать эту статью. А если нет, то сейчас вы узнаете о самых простых приемах сохранения/извлечения данных с сайтов.
1. Скачиваем сайт целиком для просмотра оффлайн
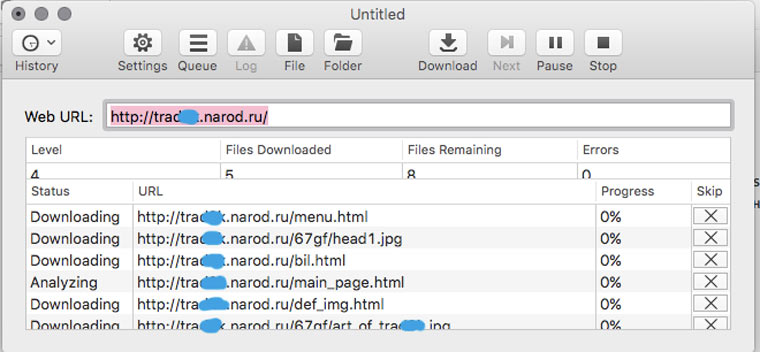
В OS X это можно сделать с помощью приложения HTTrack Website Copier, которая настраивается схожим образом.
Пользоваться Site Sucker очень просто. Открываем программу, выбираем пункт меню File -> New, указываем URL сайта, нажимаем кнопку Download и дожидаемся окончания скачивания.
Чтобы посмотреть сайт надо нажать на кнопку Folder, найти в ней файл index.html (главную страницу) и открыть его в браузере. SiteSucker скачивает только те данные, которые доступны по протоколу HTTP. Если вас интересуют исходники сайта (к примеру, PHP-скрипты), то для этого вам нужно в открытую попросить у его разработчика FTP-доступ.
2. Прикидываем сколько на сайте страниц
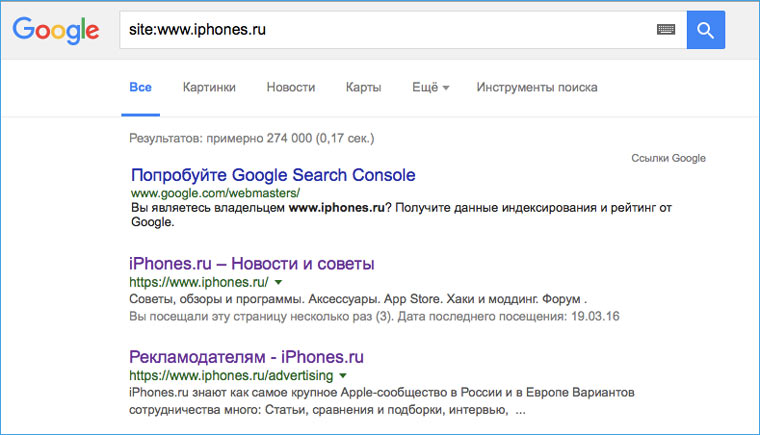
Перед тем как браться за скачивание сайта, необходимо приблизительно оценить его размер (не затянется ли процесс на долгие часы). Это можно сделать с помощью Google. Открываем поисковик и набираем команду site: адрес искомого сайта. После этого нам будет известно количество проиндексированных страниц. Эта цифра не соответствуют точному количеству страниц сайта, но она указывает на его порядок (сотни? тысячи? сотни тысяч?).
3. Устанавливаем ограничения на скачивание страниц сайта
![]()
Если вы обнаружили, что на сайте тысячи страниц, то можно ограничить число уровней глубины скачивания. К примеру, скачивать только те страницы, на которые есть ссылка с главной (уровень 2). Также можно ограничить размер загружаемых файлов, на случай, если владелец хранит на своем ресурсе tiff-файлы по 200 Мб и дистрибутивы Linux (и такое случается).
Сделать это можно в Settings -> Limits.
4. Скачиваем с сайта файлы определенного типа
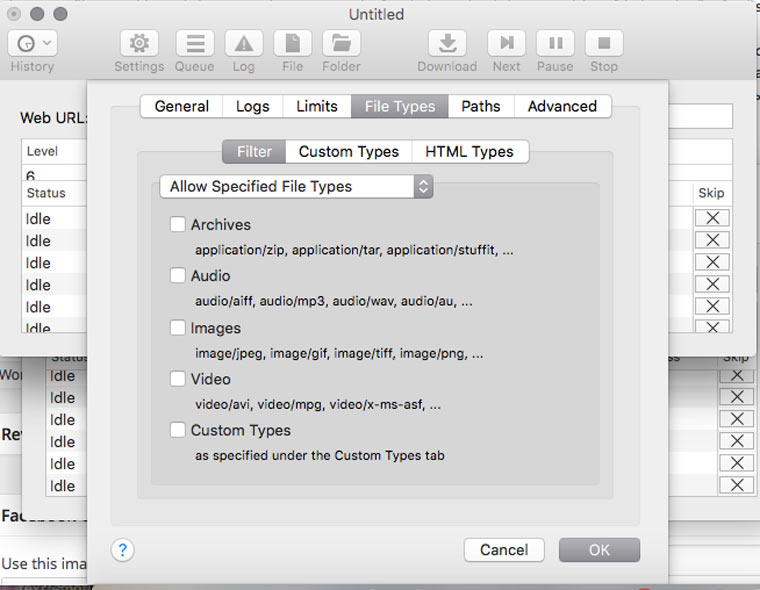
В Settings -> File Types -> Filters можно указать какие типы файлов разрешено скачивать, либо какие типы файлов запрещено скачивать (Allow Specified Filetypes/Disallow Specifies Filetypes). Таким образом можно извлечь все картинки с сайта (либо наоборот игнорировать их, чтобы места на диске не занимали), а также видео, аудио, архивы и десятки других типов файлов (они доступны в блоке Custom Types) от документов MS Word до скриптов на Perl.
5. Скачиваем только определенные папки
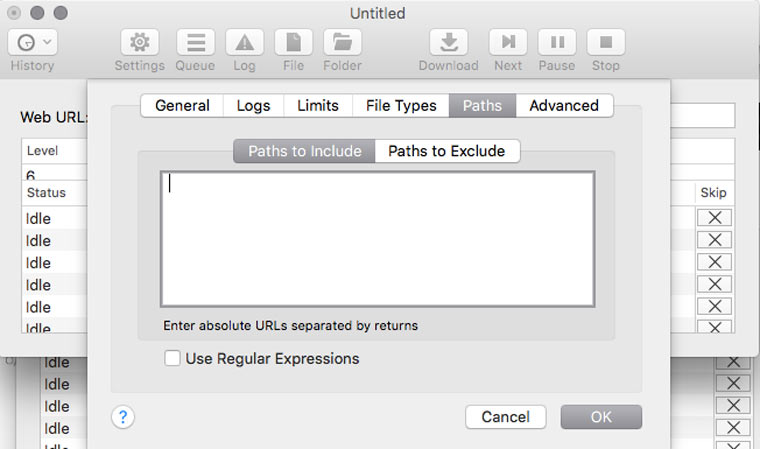
Если на сайте есть книги, чертежи, карты и прочие уникальные и полезные материалы, то они, как правило, лежат в отдельном каталоге (его можно отследить через адресную строку браузера) и можно настроить SiteSucker так, чтобы скачивать только его. Это делается в Settings -> Paths -> Paths to Include. А если вы хотите наоборот, запретить скачивание каких-то папок, то их адреса надо указать в блоке Paths to Exclude
6. Решаем вопрос с кодировкой
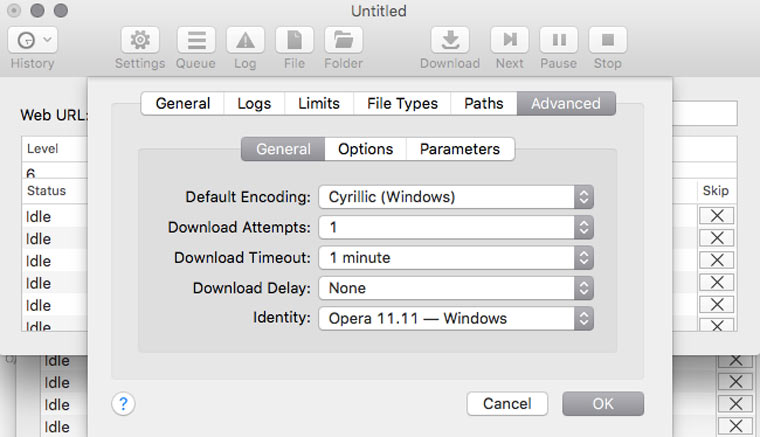
Если вы обнаружили, что скачанные страницы вместо текста содержат кракозябры, там можно попробовать решить эту проблему, поменяв кодировку в Settings -> Advanced -> General. Если неполадки возникли с русским сайтом, то скорее всего нужно указать кодировку Cyrillic Windows. Если это не сработает, то попробуйте найти искомую кодировку с помощью декодера Лебедева (в него надо вставлять текст с отображающихся криво веб-страниц).
7. Делаем снимок веб-страницы

Сделать снимок экрана умеет каждый. А знаете ли как сделать снимок веб-страницы целиком? Один из способов — зайти на web-capture.net и ввести там ссылку на нужный сайт. Не торопитесь, для сложных страниц время создания снимка может занимать несколько десятков секунд. Еще это можно провернуть в Google Chrome, а также в других браузерах с помощью дополнения iMacros.
Это может пригодиться для сравнения разных версий дизайна сайта, запечатления на память длинных эпичных перепалок в комментариях или в качестве альтернативы способу сохранения сайтов, описанного в предыдущих шести пунктах.
8. Сохраняем картинки только с определенной страницы
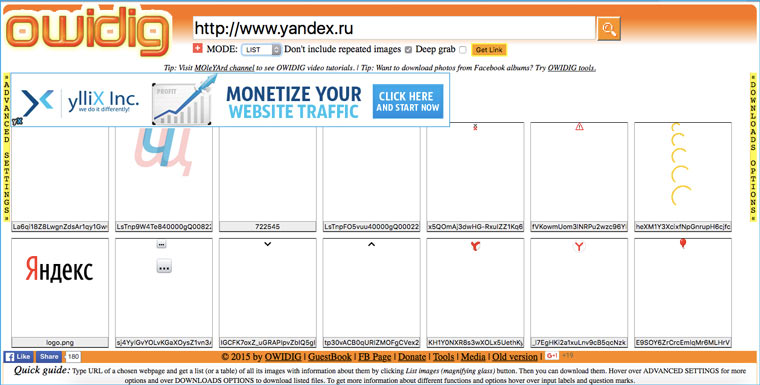
Идем на owdig.com, указываем нужную ссылку, ждем когда отобразятся все картинки и кликаем на оранжевую полоску справа, чтобы скачать их в архиве.
9. Извлекаем HEX-коды цветов с веб-сайта
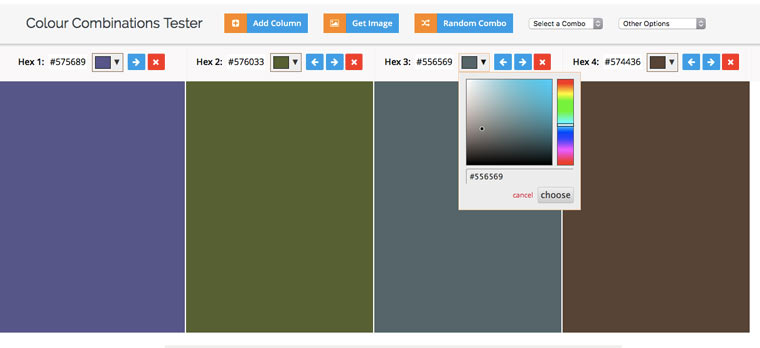
Идем на colorcombos.com и набираем адрес искомой страницы и получаем полный список цветов, которые использованы на ней.
10. Извлекаем из текста адреса электронной почты
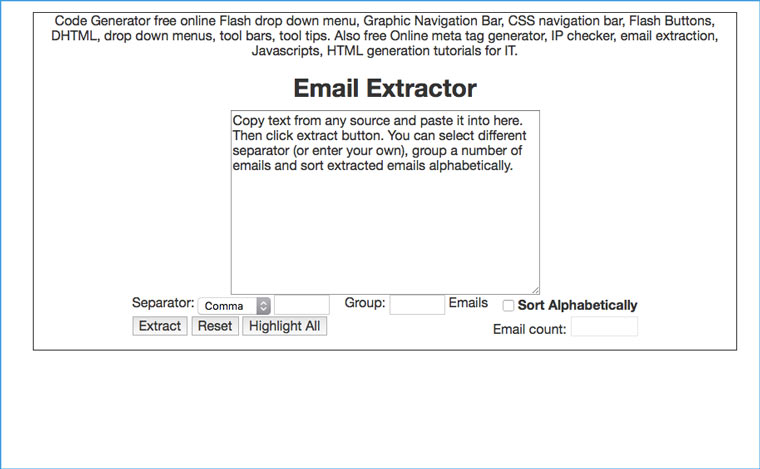
Предположим, что вам надо сделать рассылку по сотрудникам компании, а их email-адреса есть только на странице корпоративного сайта и копировать их оттуда в ручную займет лишние 20-30 минут. В такой ситуации на помощь приходит сервис emailx.discoveryvip.com. Просто вставьте туда текст и через секунду вы получите список всех адресов электронной почты, которые в нем найдены.
11. Извлекаем из текста номера телефонов
Идем на convertcsv.com/phone-extractor.htm, копируем в форму текст/html-код, содержащий номера телефонов и нажимаем на кнопку Extract.
А если надо отфильтровать в тексте заголовки, даты и прочую информацию, то к вам на помощь придут регулярные выражения и Sublime Text.
Есть и другие способы извлечения данных с сайтов. Можно попросить какую-ту информацию непосредственно у владельца ресурса, cохранять части веб-страниц с помощью iMacros и парсить сайты с помощью Google Apps Script. Еще можно пойти традиционным путем и написать для парсинга bash-скрипт, но статей об этом на iPhones.ru пока нет.





25 комментариев